Möt Acebits mittback - Mattias Liljestrand
Möt Acebits mittback - Mattias Liljestrand

Jag ska vara helt ärlig, jag är inte ett stort fan av Ansible. Eller rättare sagt - jag har aldrig riktigt snöat in på den typen av uppgifter som Ansible är bäst på.
Jag tycker inte Ansible är optimalt för att bygga ett system kring, eller att bygga IAC med. Visst, idag är många moduler idempotenta, men hundraprocentig idempotens är nästan omöjlig att uppnå utan state. När man börjar komma upp i skala i ett större system eller kommer in på lifecycle management i CI/CD pipelines börjar man märka svagheterna med Ansible jämfört med verktyg som är skapade för uppgiften.
Men nu är det ju så att Ansible finns med på DevNet Expert blueprinten, och det används jättemycket där ute, så vi provar att gå in i Ansible med ett öppet sinne och tittar på när vi faktiskt kan använda det och dra nytta av de fördelar som finns. För trots att Ansible kanske inte duger till alla usecases, är det faktiskt riktigt smidigt för vissa typer av tasks.
Grovt förenklat kan man uttrycka sig som att Ansible är ett verktyg för att scripta tasks med hjälp av olika moduler för specifika användningsområden. Ansible arbetar med ett inventory för att hålla koll på vilken eller vilka devices som hanteras av dina tasks.
Oftast ansluter Ansible till en enhet med ssh och autentiserar med ssh-nycklar, men anisble är inte begränsat till enbart ssh som accessmetod. Men oavsett om en modul använder SSH, REST, telnet eller något annat interface så ska du som användare inte behöva göra anpassningar för det.
Ansible är procedurdrivet, med det menas att vi skapar tasks som vi kör enligt en specifik procedur eller ordning.
För att instruera ansible skriver vi en playbook som skrivs i YAML och ansible-lingon är ganska enkel att förstå. En playbook innehåller en eller flera ‘plays’, en play är en eller flera tasks som ska köras för en eller en grupp av enheter. Tasks utförs sedan med hjälp av en modul som innehåller funktionalitet för den uppgiften du tänkt utföra.
Ansible använder moduler för att utföra uppgifter. För olika typer av devices finns olika moduler som är paketerade med en eller flera metoder vi kan använda för att utföra våra tasks. Vi kan till exempel använda modulen ‘cisco.ios.ios_config’ för att administrera en cisco device:
---
- hosts: routers
tasks:
- name: configure ip helpers on multiple interfaces
cisco.ios.ios_config:
lines:
- ip helper-address 192.0.2.1
- ip helper-address 192.0.2.2
parents: "{{ item }}"
with_items:
- interface e0/1.10
- interface e0/1.20
- interface e0/1.30
- name: backup
ios_config:
backup: yes
Med exemplet ovan har vi en play som appliceras på alla enheter i gruppen ‘routers’, för dessa kör vi två tasks, en som applicerar ip-helpers och därefter gör vi en backup.
I första tasken talar vi om att vi vill använda modulen ios_config, och med den vill vi konfigurera ip-helpers på en lista interfaces. Vi får ett väldigt enkelt och straight-forward sätt att definiera våra tasks på ett överskådligt sätt och kan enkelt justera ordningen för vad som utförs och för vilka enheter.
Här bidrar modulerna till att abstrahera bort koden från playbooken med ett tydligt gränssnitt, olika moduler också oberoende av varandra eftersom interfacet för hur en ansiblemodul ska fungera är tydligt definierat.
Om vi ska lära oss Ansible nu så behöver vi labba med det. Här tänker jag mig att vi sätter upp Ansible med ett inventory och en enkel playbook.
├── ansible.cfg
├── group_vars
│ └── all.yml
├── inventory.yml
└── playbook.yml
1 directory, 4 files
Jag kommer idag inte att gå igenom i detalj hur du kommer igång med ansible, det finns det redan så många bloggar om. Men hör gärna av dig om du vill ha hjälp!
I inventory.yml har jag alltså mina routrar som jag labbar med och allt är uppsatt så att min playbook skriver konfiguration till en router i mitt labb. Playbooken är samma som vi tittade på alldeles nyss - en task som använder cisco ios_config för att lägga till ip helpers på en lista interfaces.
Först testar jag att köra playbooken lokalt och det funkar bra, härligt!
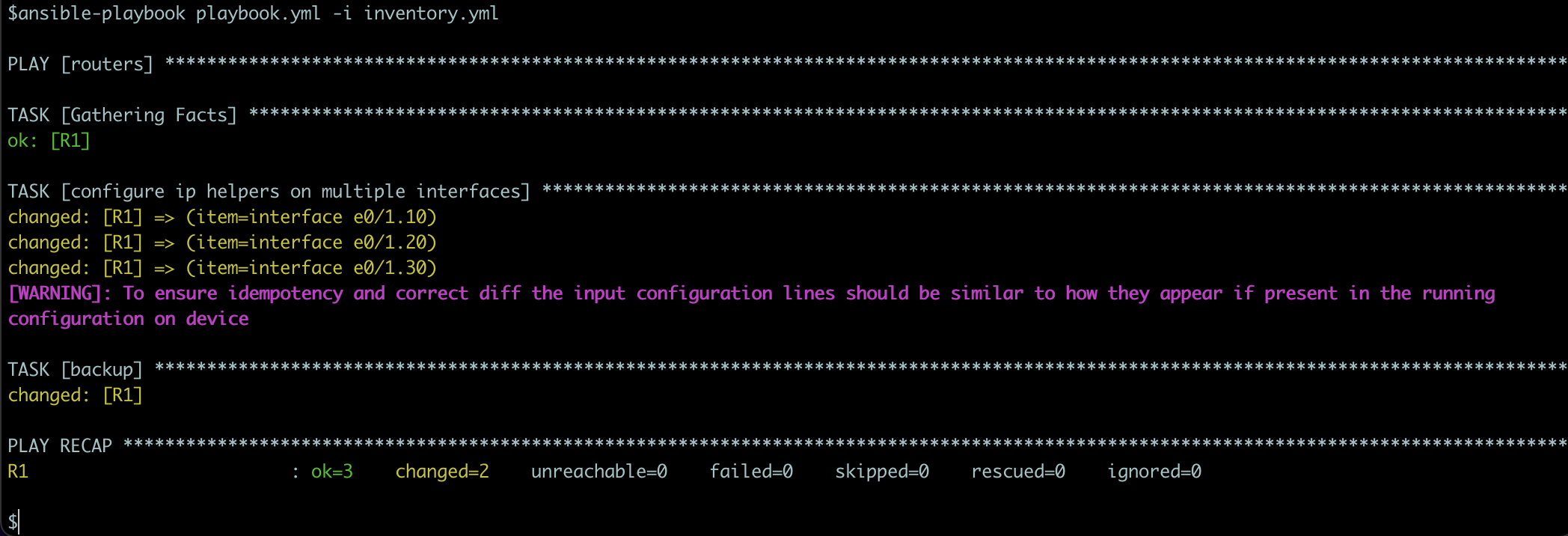
Jag ser att helpers konfigurerats på rätt interface, toppen!
Nu leker vi med tanken att vi jobbat ett tag och har playbooks för alla möjliga typer av tasks, livet leker helt enkelt jämfört med de gamla tiderna när vi var tvugna att ssh:a och copy-pastea till höger och vänster.
Nu kommer dock dagen då du ska byta den ena helpern mot en ny. Enkelt tänker du, och byter ip adresserna i listan i din playbook enligt:
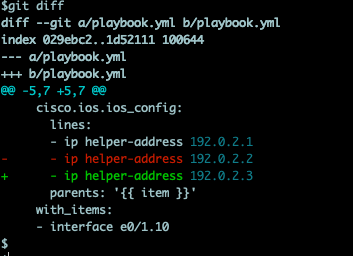
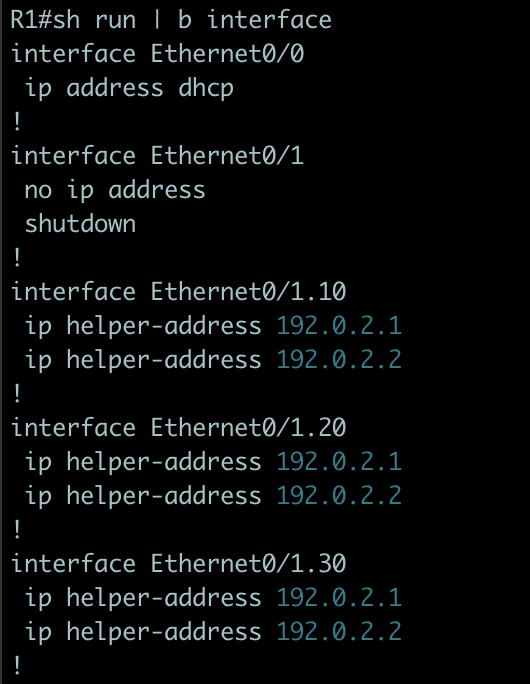
Sen kör vi playbooken igen och tänker att nu är allting frid och fröjd fram tills du får ett samtal om att en massa maskiner fått IP adresser från de gamla scopen. “omöjligt” tänker du, “jag har ju bytt”. Och loggar in i en av routrarna för att dubbelkolla och möts av:
R1#sh run int e0/1.10
Building configuration...
Current configuration : 119 bytes
!
interface Ethernet0/1.10
ip helper-address 192.0.2.1
ip helper-address 192.0.2.2
ip helper-address 192.0.2.3
end
R1#
Här ser vi tydligt vad som hänt. Ansible har ju i den andra körningen inte något minne av vad vi gjort tidigare, utan får ju en lista av kommandon som ska köras, vilket den gör, men att det finns helpers definierade sedan tidigare som du ändrat har ju ansible ingen aning om. Detta är ju ett förväntat betéende eftersom vi annars hade riskerat att ta bort konfiguration som gjorts manuellt eller med andra verktyg.
För att rätta till det här måste vi se ansible som det procedurdrivna verktyg det är och köra ansible tasken så här:
- name: configure ip helpers on multiple interfaces
cisco.ios.ios_config:
lines:
- ip helper-address 192.0.2.1
- ip helper-address 192.0.2.3
- no ip helper-address 192.0.2.2
parents: "{{ item }}"
with_items:
- interface e0/1.10
- interface e0/1.20
- interface e0/1.30
Ansible fungerar ju väldigt smidigt till att administrera många enheter samtidigt på ett strukturerat sätt. Vi ser stora fördelar mot att manuellt logga in i varje enhet och köra kommandon, vi kan också nyttja loopar och variabler för att göra det ännu smidigare. Vi ser dock också att Ansible inte kommer vara det smidigaste att jobba med i CI/CD pipelines, det går för rätt typ av uppgifter så klart, men då behöver vi ha i åtanke vad som kommer hända beroende på vad vi gör i våra tasks så vi inte råkar ut för liknande problem som i exemplet ovan.
Vid enklare tasks kan det lämpa sig att köra ansible i en pipeline, låt säga att du t.ex. bootstrappar servrar och vill säkerställa att en fil alltid finns där, då kan ansible vara ett enkelt sätt att kopiera den senaste filen till servern.
Det kan också vara bra för att sätta upp och administrera miljöer upp till nivån där du senare producerar tjänster mer som tjänst. Till exempel har jag använt ansible för att sätta upp mitt kuberneteskluster i vår labbmiljö, men jag använder inte ansible för att deploya och administrera instanser av tjänster. För tjänstelagret vill vi oftast hålla koll på vad som skapats, alla dess attribut och när de ska tas bort - hela livscykeln. Då finns det oftast bättre alternativ!
Sammanfattningsvis tycker jag att ansible kan vara ett väldigt bra verktyg för att sätta upp och underhålla infrastruktur som du sedan inte ändrar speciellt mycket. Saker som du kör kontrollerat och håller koll på när och hur det körs. Vi kan använda ansible i system, men då bör tjänsten vi tillhandahåller inte försöka vara “intentbased” eller deklarativ, utan mer av typen “fire and forget”.
Så innan du börjar, fundera alltid på vad du faktiskt vill åstadkomma innan du snöar in på vilket verktyg du ska använda!
Möt Acebits mittback - Mattias Liljestrand
Acebit rekryterar teknisk säljare – Kalle Gustafsson
Plugga sex nätter? Acebit på Baekdahl Devnet Expert Bootcamp
Robert bygger branschens bästa arbetsplats på Acebit
Med passion för automation – möt Gustav Larsson
Möt spindeln i Acebits nät - Joakim Hag
Acebit expanderar – automationsess från Dalarna öppnar i Stockholm
Acebit rekryterar Isak Ljunggren – Acebit Trainee från Högskolan Dalarna
Även Falu-Kuriren har intresserat sig för Acebit och besökt oss i Falun!
Emanuel Lipschütz ny styrelseordförande i Acebit
Nyligen stötte jag på ett scenario som innebar att ca 200 Meraki-enheter behövde byta inställning från DHCP till statisk IP-adressering. Istället för att gör...
I mina tidigare inlägg om virtuella port-channels kikade vi på vad det är och vilka delar de utgör. Det här avsnittet kommer beröra hur en grundkonfiguration...
Bakgrund Idag tänkt jag skriva några rader om att skriva concurrent kod, eller “samtidighet” om vi prompt ska översätta det till svenska. För att enklare för...
Scrapli Automation - trunk ports